Databricks provides both REST api and cli method to automate creation of workspace and clusters but required a manual step of PAT (Personal Access Token) creation. When you provide a fixed size cluster, Databricks ensures that your cluster has the specified number of workers.
databricks azure The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. Namely: Is it possible to move my ETL process from SSIS to ADF? Databricks 2022. In particular, you must add the permissions ec2:AttachVolume, ec2:CreateVolume, ec2:DeleteVolume, and ec2:DescribeVolumes. Create an SSH key pair by running this command in a terminal session: You must provide the path to the directory where you want to save the public and private key. The driver node maintains state information of all notebooks attached to the cluster.
{kind=link}
If a cluster has zero workers, you can run non-Spark commands on the driver node, but Spark commands will fail. Cannot access Unity Catalog data.  To reference a secret in the Spark configuration, use the following syntax: For example, to set a Spark configuration property called password to the value of the secret stored in secrets/acme_app/password: For more information, see Syntax for referencing secrets in a Spark configuration property or environment variable. Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster. Using Databricks with Azure free trial subscription, we cannot use a cluster that utilizes more than 4 cores. This section describes the default EBS volume settings for worker nodes, how to add shuffle volumes, and how to configure a cluster so that Databricks automatically allocates EBS volumes. Paste the key you copied into the SSH Public Key field. Example use cases include library customization, a golden container environment that doesnt change, and Docker CI/CD integration. You cannot change the cluster mode after a cluster is created. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. First, Photon operators start with Photon, for example, PhotonGroupingAgg. If you dont want to allocate a fixed number of EBS volumes at cluster creation time, use autoscaling local storage. 2016-2022 Unravel Data Inc. All rights reserved.
To reference a secret in the Spark configuration, use the following syntax: For example, to set a Spark configuration property called password to the value of the secret stored in secrets/acme_app/password: For more information, see Syntax for referencing secrets in a Spark configuration property or environment variable. Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster. Using Databricks with Azure free trial subscription, we cannot use a cluster that utilizes more than 4 cores. This section describes the default EBS volume settings for worker nodes, how to add shuffle volumes, and how to configure a cluster so that Databricks automatically allocates EBS volumes. Paste the key you copied into the SSH Public Key field. Example use cases include library customization, a golden container environment that doesnt change, and Docker CI/CD integration. You cannot change the cluster mode after a cluster is created. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. First, Photon operators start with Photon, for example, PhotonGroupingAgg. If you dont want to allocate a fixed number of EBS volumes at cluster creation time, use autoscaling local storage. 2016-2022 Unravel Data Inc. All rights reserved.  before click Run All button to execute the whole notebook. Creating a new cluster takes a few minutes and afterwards, youll see newly-created service on the list: Simply, click on the service name to get basic information about the Databricks Workspace. Cluster creation will fail if required tags with one of the allowed values arent provided. That is, EBS volumes are never detached from an instance as long as it is part of a running cluster. It can be understood that you are using a Standard cluster which consumes 8 cores (4 worker and 4 driver cores). The default value of the driver node type is the same as the worker node type. Both cluster create permission and access to cluster policies, you can select the Unrestricted policy and the policies you have access to. azure service principle for authentication (Reference. When accessing a view from a cluster with Single User security mode, the view is executed with the users permissions. Scales down based on a percentage of current nodes. Convert all small words (2-3 characters) to upper case with awk or sed. databricks azure databricks If you select a pool for worker nodes but not for the driver node, the driver node inherit the pool from the worker node configuration. It focuses on creating and editing clusters using the UI. When you configure a clusters AWS instances you can choose the availability zone, the max spot price, EBS volume type and size, and instance profiles. To ensure that all data at rest is encrypted for all storage types, including shuffle data that is stored temporarily on your clusters local disks, you can enable local disk encryption. The [shopping] and [shop] tags are being burninated, Azure Data Factory using existing cluster in Databricks. Copy the Hostname field.
before click Run All button to execute the whole notebook. Creating a new cluster takes a few minutes and afterwards, youll see newly-created service on the list: Simply, click on the service name to get basic information about the Databricks Workspace. Cluster creation will fail if required tags with one of the allowed values arent provided. That is, EBS volumes are never detached from an instance as long as it is part of a running cluster. It can be understood that you are using a Standard cluster which consumes 8 cores (4 worker and 4 driver cores). The default value of the driver node type is the same as the worker node type. Both cluster create permission and access to cluster policies, you can select the Unrestricted policy and the policies you have access to. azure service principle for authentication (Reference. When accessing a view from a cluster with Single User security mode, the view is executed with the users permissions. Scales down based on a percentage of current nodes. Convert all small words (2-3 characters) to upper case with awk or sed. databricks azure databricks If you select a pool for worker nodes but not for the driver node, the driver node inherit the pool from the worker node configuration. It focuses on creating and editing clusters using the UI. When you configure a clusters AWS instances you can choose the availability zone, the max spot price, EBS volume type and size, and instance profiles. To ensure that all data at rest is encrypted for all storage types, including shuffle data that is stored temporarily on your clusters local disks, you can enable local disk encryption. The [shopping] and [shop] tags are being burninated, Azure Data Factory using existing cluster in Databricks. Copy the Hostname field.
{kind=link}
{kind=link}
Read more about AWS availability zones. The policy rules limit the attributes or attribute values available for cluster creation. 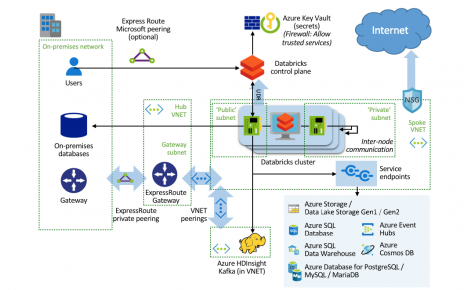
To specify configurations. Azure Databricks, could not initialize class org.apache.spark.eventhubs.EventHubsConf. You can add up to 45 custom tags. https://northeurope.azuredatabricks.net/?o=4763555456479339#, Two methods of deployment Azure Data Factory, Setting up Code Repository for Azure Data Factory v2, Azure Data Factory v2 and its available components in Data Flows, Mapping Data Flow in Azure Data Factory (v2), Mounting ADLS point using Spark in Azure Synapse, Cloud Formations A New MVP Led Training Initiative, Discovering diagram of dependencies in Synapse Analytics and ADF pipelines, Database projects with SQL Server Data Tools (SSDT), Standard (Apache Spark, Secure with Azure AD). In addition, only High Concurrency clusters support table access control. Run the following command, replacing the hostname and private key file path. Thanks for contributing an answer to Stack Overflow! This article explains the configuration options available when you create and edit Databricks clusters. https://docs.microsoft.com/en-us/azure/databricks/clusters/single-node. These cookies will be stored in your browser only with your consent. Cluster creation errors due to an IAM policy show an encoded error message, starting with: The message is encoded because the details of the authorization status can constitute privileged information that the user who requested the action should not see. During cluster creation or edit, set: See Create and Edit in the Clusters API reference for examples of how to invoke these APIs. If you change the value associated with the key Name, the cluster can no longer be tracked by Databricks.
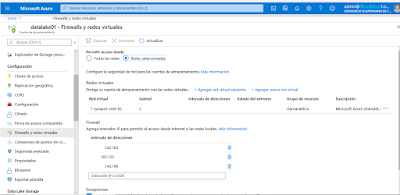{kind=link}
A cluster policy limits the ability to configure clusters based on a set of rules. What is Apache Spark Structured Streaming? Databricks runtimes are the set of core components that run on your clusters. All Databricks runtimes include Apache Spark and add components and updates that improve usability, performance, and security. The IAM policy should include explicit Deny statements for mandatory tag keys and optional values. If a worker begins to run too low on disk, Databricks automatically attaches a new EBS volume to the worker before it runs out of disk space. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers. A Single Node cluster has no workers and runs Spark jobs on the driver node.
For information on the default EBS limits and how to change them, see Amazon Elastic Block Store (EBS) Limits.
You SSH into worker nodes the same way that you SSH into the driver node. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? Edit the security group and add an inbound TCP rule to allow port 2200 to worker machines. As an example, we will read a CSV file from the provided Website (URL): Pressing SHIFT+ENTER executes currently edited cell (command). Lets create the first cluster. Creating Databricks cluster involves creating resource group, workspace and then creating cluster with the desired configuration. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. As you can see writing and running your first own code in Azure Databricks is not as much tough as you could think.
High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala. Safe to ride aluminium bike with big toptube dent? To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances, for the driver and worker nodes. User Isolation: Can be shared by multiple users. See AWS spot pricing. You can do this at least two ways: Then, name the new notebook and choose the main language in it: Available languages are Python, Scala, SQL, R. rev2022.7.29.42699. Find centralized, trusted content and collaborate around the technologies you use most. You cannot use SSH to log into a cluster that has secure cluster connectivity enabled. To learn more, see our tips on writing great answers. Then, click the Add button, which gives you the opportunity to create a new Databricks service. If the cluster is terminated you need to run it first. Go to the notebook and on the top menu, check the first option on the left: Azure Databricks: Assign cluster to notebook, Choose a cluster you need. Access to cluster policies only, you can select the policies you have access to. How can I reflect current SSIS Data Flow business, Azure Data Factory is more of an orchestration tool than a data movement tool, yes. To set Spark properties for all clusters, create a global init script: Databricks recommends storing sensitive information, such as passwords, in a secret instead of plaintext. SSH allows you to log into Apache Spark clusters remotely for advanced troubleshooting and installing custom software. Cloud Provider Launch Failure: A cloud provider error was encountered while setting up the cluster. To add shuffle volumes, select General Purpose SSD in the EBS Volume Type drop-down list: By default, Spark shuffle outputs go to the instance local disk.
Azure DevOps pipeline integration with Databricks + how to print Databricks notebook result on pipeline result screen, Retrieve Cluster Inactivity Time on Azure Databricks Notebook, Problem starting cluster on azure databricks with version 6.4 Extended Support (includes Apache Spark 2.4.5, Scala 2.11). This model allows Databricks to provide isolation between multiple clusters in the same workspace. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads. Would you like to provide feedback? Lets create our first notebook in Azure Databricks. This instance profile must have both the PutObject and PutObjectAcl permissions. Under Advanced options, select from the following cluster security modes: None: No isolation. databricks databricks delta azure apr updated automate creation tables loading Job > Configure Cluster > Spark >Spark Conf, Job > Configure Cluster > Spark > Logging, Job > Configure Cluster > Spark > Init Scripts, Part 1: Installing Unravel Server on CDH+CM, Part 2: Enabling additional instrumentation, Adding a new node in an existing CDH cluster, Troubleshooting Cloudera Distribution of Apache Hadoop (CDH) issues, Adding a new node in an existing HDP cluster monitored by Unravel, Part 1: Installing Unravel Server on MapR, Installing Unravel Server on an EC2 instance, Connecting Unravel Server to a new or existing EMR cluster, Deploying Unravel from the AWS Marketplace, Creating private subnets for Unravel's Lambda function, Connecting Unravel Server to a new Dataproc cluster, Part 1: Installing Unravel on a Separate Azure VM, Part 2: Connecting Unravel to an HDInsight cluster, Deploying Unravel for Azure HDInsight from Azure Marketplace, Adding a new node in an existing HDI cluster monitored by Unravel, Setting up Azure MySQL for Unravel (Optional), Deploying Unravel for Azure Databricks from Azure Marketplace, Configure Azure Databricks Automated (Job) Clusters with Unravel, Library versions and licensing for OnDemand, Detecting resource contention in the cluster, Detecting apps using resources inefficiently, End-to-end monitoring of HBase databases and clusters, Best practices for end-to-end monitoring of Kafka, Kafka detecting lagging or stalled partitions, Using Unravel to tune Spark data skew and partitioning, How to intelligently monitor Kafka/Spark Streaming data pipeline, Using RDD caching to improve a Spark app's performance, Enabling the JVM sensor on HDP cluster-wide for MapReduce2 (MR), Integrating with Informatica Big Data Management, Deploying Unravel on security-enhanced Linux, Enabling multiple daemons for high-volume data, Configuring another version of OpenJDK for Unravel, Running verification scripts and benchmarks, Creating an AWS RDS CloudWatch Alarm for Free Storage Space, Elasticsearch storage requirements on the Unravel Node, Populating the Unravel Data Insights page, Configuring access for an Oracle database, Creating Active Directory Kerberos principals and keytabs for Unravel, Enable authentication for the Unravel Elastic daemon, Encrypting passwords in Unravel properties and settings, Importing a private certificate into Unravel truststore, Running Unravel daemons with a custom user, Using a private certificate authority with Unravel, Configuring forecasting and migration planning reports, Enabling LDAP authentication for Unravel UI, Enabling SAML authentication for Unravel Web UI, Configure Spark properties for Spark Worker daemon @ Unravel, Enable/disable live monitoring of Spark Streaming applications, Stopping, restarting, and configuring the AutoAction daemon. In Spark config, enter the configuration properties as one key-value pair per line. Member of Data Community Poland, co-organizer of SQLDay, Happy husband & father. More like San Francis-go (Ep. When you create a Databricks cluster, you can either provide a fixed number of workers for the cluster or provide a minimum and maximum number of workers for the cluster. If you cant see it go to All services and input Databricks in the searching field. For some Databricks Runtime versions, you can specify a Docker image when you create a cluster. Copy the entire contents of the public key file.
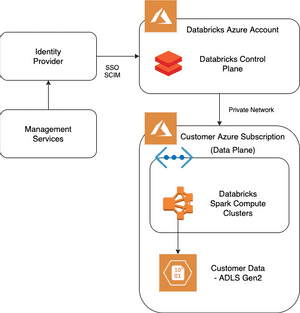{kind=link}
{kind=link}
cluster azure databricks create microsoft docs running indicates state Try to do this on the first cell (print Hello world). Databricks also provides predefined environment variables that you can use in init scripts. dbfs:/cluster-log-delivery, cluster logs for 0630-191345-leap375 are delivered to
{kind=link}
Its like using SSIS, with control flows only. If you reconfigure a static cluster to be an autoscaling cluster, Databricks immediately resizes the cluster within the minimum and maximum bounds and then starts autoscaling. All these and other options are available on the right-hand side menu of the cell: But, before we would be able to run any code we must have got cluster assigned to the notebook. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. To securely access AWS resources without using AWS keys, you can launch Databricks clusters with instance profiles. Data Platform MVP, MCSE. The nodes primary private IP address is used to host Databricks internal traffic. A Standard cluster is recommended for a single user. Once you click outside of the cell the code will be visualized as seen below: Azure Databricks: MarkDown in command (view mode). Lets start with the Azure portal. What was the large green yellow thing streaking across the sky? At any time you can terminate the cluster leaving its configuration saved youre not paying for metadata. Single-user clusters support workloads using Python, Scala, and R. Init scripts, library installation, and DBFS FUSE mounts are supported on single-user clusters. A cluster node initializationor initscript is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts. This section describes how to configure your AWS account to enable ingress access to your cluster with your public key, and how to open an SSH connection to cluster nodes. See the IAM Policy Condition Operators Reference for a list of operators that can be used in a policy. databricks sql
{kind=link}
If you attempt to select a pool for the driver node but not for worker nodes, an error occurs and your cluster isnt created. This feature is also available in the REST API. In addition, on job clusters, Databricks applies two default tags: RunName and JobId. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. All rights reserved. We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. GeoSpark using Maven UDF running Databricks on Azure? Databricks uses Throughput Optimized HDD (st1) to extend the local storage of an instance. Only SQL workloads are supported.
Databricks may store shuffle data or ephemeral data on these locally attached disks.
Databricks worker nodes run the Spark executors and other services required for the proper functioning of the clusters. The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster makes down-scaling decisions.
An example instance profile To learn more about working with Single Node clusters, see Single Node clusters.
For clusters launched from pools, the custom cluster tags are only applied to DBU usage reports and do not propagate to cloud resources. https://docs.microsoft.com/en-us/answers/questions/35165/databricks-cluster-does-not-work-with-free-trial-s.html. This applies especially to workloads whose requirements change over time (like exploring a dataset during the course of a day), but it can also apply to a one-time shorter workload whose provisioning requirements are unknown.
This is generated from a Databricks setup script on Unravel. databricks azure data devops level security isolation network In contrast, a Standard cluster requires at least one Spark worker node in addition to the driver node to execute Spark jobs. By default, the max price is 100% of the on-demand price. Microsoft Learn: Azure Databricks.
You can compare number of allocated workers with the worker configuration and make adjustments as needed.
To do this, see Manage SSD storage. As a consequence, the cluster might not be terminated after becoming idle and will continue to incur usage costs. Here is an example of a cluster create call that enables local disk encryption: If your workspace is assigned to a Unity Catalog metastore, you use security mode instead of High Concurrency cluster mode to ensure the integrity of access controls and enforce strong isolation guarantees. Library installation, init scripts, and DBFS FUSE mounts are disabled to enforce strict isolation among the cluster users. databricks Cluster create permission, you can select the Unrestricted policy and create fully-configurable clusters. Your workloads may run more slowly because of the performance impact of reading and writing encrypted data to and from local volumes. Asking for help, clarification, or responding to other answers. databricks azure
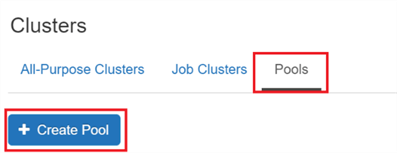{kind=link}
{kind=link}
Certain parts of your pipeline may be more computationally demanding than others, and Databricks automatically adds additional workers during these phases of your job (and removes them when theyre no longer needed). For our demo purposes do select Standard and click Create button on the bottom. If it is larger, cluster startup time will be equivalent to a cluster that doesnt use a pool. It needs to be copied on each Automated Clusters. The secondary private IP address is used by the Spark container for intra-cluster communication.