1 Components of a crawler-based search engine. Crawler-based Search Engine menelusuri internet untuk menemukan halaman website ter-update demi memperbaharui informasi dalam database milik search engine sehingga Anda sebagai user dari sebuah search engine dapat mendapatkan informasi paling terbaru. Examples of Web Based Search Engines: Google: Very Firstly and most obviously, Google is the most used and most popular search Engine around the Globe that uses Crawlers or bots to index results on a A search crawler is a bot that scans web pages and adds these to search indexes. 4. It is the latest web-based search engine that also delivers Yahoos results. As crawler -based search engines cannot access these documents, specialized sources such as these currently provide our only access. Also called the spider. Crawler based search engines: All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database.  A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. Information from a lower on a vital part. Search Engines. The human-powered search engines depend on human editors who decide what category web pages will be assigned to. Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Listed below are some of the top crawler-based search engines, along with their respective Web crawling bots. The major search engines on the Web all have such a program, which is also known as a "spider" or a "bot." The web community often asks for SEO best practices for their web sites.
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. Information from a lower on a vital part. Search Engines. The human-powered search engines depend on human editors who decide what category web pages will be assigned to. Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Listed below are some of the top crawler-based search engines, along with their respective Web crawling bots. The major search engines on the Web all have such a program, which is also known as a "spider" or a "bot." The web community often asks for SEO best practices for their web sites.  One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. Computer programs spiders build them not by human selection. You can extract data from more than one page, keywords, and categories. Stored web addresses related to search terms are found and displayed.
One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. Computer programs spiders build them not by human selection. You can extract data from more than one page, keywords, and categories. Stored web addresses related to search terms are found and displayed. 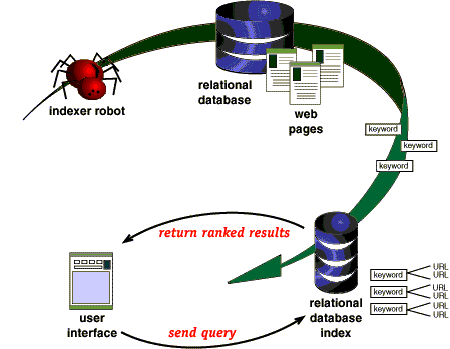 The crawler visits pages, "reads" it and Google is the most used search engine worldwide with a 92 percent market share in mid-2019. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages. Examples of crawler-based search engines are: Google (www.google.com) ; Video search engines: Find music videos, news videos, live streams, and more. The major search engines on the Web all have such a program, which is also known as a "spider" Search engine optimization (SEO) software, or organic search marketing software, is designed to improve the ranking of websites in search engine results pages (SERPs) without paying the search engine provider for placement.
The crawler visits pages, "reads" it and Google is the most used search engine worldwide with a 92 percent market share in mid-2019. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages. Examples of crawler-based search engines are: Google (www.google.com) ; Video search engines: Find music videos, news videos, live streams, and more. The major search engines on the Web all have such a program, which is also known as a "spider" Search engine optimization (SEO) software, or organic search marketing software, is designed to improve the ranking of websites in search engine results pages (SERPs) without paying the search engine provider for placement.  They select the pages to include in the index randomly. The This is a question our experts keep getting from time to time. Popular choices of crawler-based search engines are: Google, Bing, Yandex, Yahoo!, Baidu. Answer (1 of 3): Advantages for crawler operators: * You get to gather the data you want Disadvantages for crawler operators: * Your traffic may be identified as abusive or suspicious and blocked * You may be constrained by your limits in bandwidth, processing, or storage Advantages for This means that the cost of each click and the position your ad will appear depends on demand and supply. About. Page 1 of 6. Some of the most popular examples of search engines are Google, Bing, Yahoo!, & MSN Search. This can help business owners to measure SEO success. These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. Google may be one of the most popular search engines but there are many more alternative search engines available for A web crawler, also referred to as a search engine bot or a website spider, is a digital bot that crawls across the World Wide Web to find and index pages for search engines.. Search engines dont magically know what websites exist on the Internet. The spider visits a web page, reads it, and then follows links to other pages within the site. This involves real-time data tracking with high-level insights. Crawling. Indexing. There are four basic steps, every crawler based search engines follow before displaying any sites in the search results. Text and keywords are selected and recorded in huge data centers. All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. Search Engine Working. In the process of doing so, the search engine analyzes that page's contents. Other formats Text file.
They select the pages to include in the index randomly. The This is a question our experts keep getting from time to time. Popular choices of crawler-based search engines are: Google, Bing, Yandex, Yahoo!, Baidu. Answer (1 of 3): Advantages for crawler operators: * You get to gather the data you want Disadvantages for crawler operators: * Your traffic may be identified as abusive or suspicious and blocked * You may be constrained by your limits in bandwidth, processing, or storage Advantages for This means that the cost of each click and the position your ad will appear depends on demand and supply. About. Page 1 of 6. Some of the most popular examples of search engines are Google, Bing, Yahoo!, & MSN Search. This can help business owners to measure SEO success. These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. Google may be one of the most popular search engines but there are many more alternative search engines available for A web crawler, also referred to as a search engine bot or a website spider, is a digital bot that crawls across the World Wide Web to find and index pages for search engines.. Search engines dont magically know what websites exist on the Internet. The spider visits a web page, reads it, and then follows links to other pages within the site. This involves real-time data tracking with high-level insights. Crawling. Indexing. There are four basic steps, every crawler based search engines follow before displaying any sites in the search results. Text and keywords are selected and recorded in huge data centers. All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. Search Engine Working. In the process of doing so, the search engine analyzes that page's contents. Other formats Text file.
Well not in the way you might be thinking anyway. Keywords used in the website are similar to what people might be searching for. There is the crawler (also called a spider or a bot). Ryan CapletCSE 4904 Fall 08Milestone 1Sept 17, 2008Crawler Based Search EngineBackground:The purpose of this project is to design a crawler-based search engi Web scraping is extracting data from websites. The web-crawler is the part that gathers the data, data which is then All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website. Crawler-based search engines . A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support. Google gave me 3 one-month old articles then listed other non-related topics; Bing gave me four. crawler-based search engines. AJAX Select to obey Googles now deprecated AJAX Crawling Scheme. What is a Crawler-based Engine? 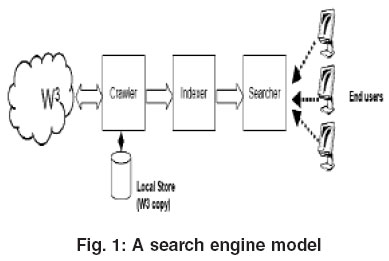 These types of search engines gather their listings in different ways, through crawler-based searches, human-powered directories, and hybrid searches [9]. Email security is the practice of preventing email-based cyber attacks, protecting email accounts from takeover, and securing the contents of emails. They "crawl" or "spider" the web, then people search thru what they have found. Network Layer. Interface. fetch.php It was founded in 2000 and now has more than 16 billion pages currently indexed. Indexing is the next step after crawling which is a process of identifying the words and expressions that 1.3. AI-based SEO can ensure that one gets precise ROI tracking. Ease of use.
These types of search engines gather their listings in different ways, through crawler-based searches, human-powered directories, and hybrid searches [9]. Email security is the practice of preventing email-based cyber attacks, protecting email accounts from takeover, and securing the contents of emails. They "crawl" or "spider" the web, then people search thru what they have found. Network Layer. Interface. fetch.php It was founded in 2000 and now has more than 16 billion pages currently indexed. Indexing is the next step after crawling which is a process of identifying the words and expressions that 1.3. AI-based SEO can ensure that one gets precise ROI tracking. Ease of use. 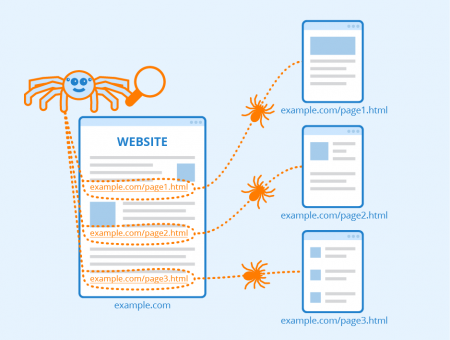 Expert Answers: A web crawler (also known as a web spider, spider bot, web bot, or simply a crawler) is a computer software program that is used by a search engine to index. Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. Todays search engines rely on software packages called spiders or robots.
Expert Answers: A web crawler (also known as a web spider, spider bot, web bot, or simply a crawler) is a computer software program that is used by a search engine to index. Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. Todays search engines rely on software packages called spiders or robots.
What is a search crawler? Crawler search engines rely on sophisticated computer programs called "spiders," "crawlers," or "bots" that surf the Internet, locating webpages, links, and other content that are then stored in the SE's page repository. Python script solution that captures/craws data from Instagram. Human powered directories. A user makes a single query request which is distributed to the search engines, databases or other query engines participating in the federation.The federated search then aggregates the results that are received from the search engines for Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.Examples of crawler-based search engines are: Google (www.google.com) Scrapy : Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. A metasearch engine (or search aggregator) is an online information retrieval tool that uses the data of a web search engine to produce its own results. 18. Human Powered Directories Open directory system is also known as human powered directories whis is based on human activities for listing. Crawler based search engine.  A piece of software called a crawler 1.2. What is the best search engine that doesnt track you?1) DuckDuckGo is a search engine that allows you to find ducks and ducklings.DuckDuckGo is one of the most well-known and safe search engines on the internet today.Yahoo!Search is a handy metasearch engine that aggregates results from more than 400 different sources including Yahoo!Search, Bing! Crawler based search engines Their listings automatically.
A piece of software called a crawler 1.2. What is the best search engine that doesnt track you?1) DuckDuckGo is a search engine that allows you to find ducks and ducklings.DuckDuckGo is one of the most well-known and safe search engines on the internet today.Yahoo!Search is a handy metasearch engine that aggregates results from more than 400 different sources including Yahoo!Search, Bing! Crawler based search engines Their listings automatically.
 Ryan CapletCSE 4904 Fall 08Milestone 1Sept 17, 2008Crawler Based Search EngineBackground:The purpose of this project is to design a crawler-based search engi
Ryan CapletCSE 4904 Fall 08Milestone 1Sept 17, 2008Crawler Based Search EngineBackground:The purpose of this project is to design a crawler-based search engi  Basic principles in the working of a Search Engine. A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the search Danny Sullivan. The Parts of a Crawler-Based Search Engines. search.php. 2. Program yang digunakan oleh mesin pencari untuk mengakses laman web disebut spider, namun pada kondisi tertentu dikenal dengan nama lain seperti crawler, robot atau bot. What is search engine give 5 examples? Tor Browser:- Tor browser is the main key point of entering the dark web.
Basic principles in the working of a Search Engine. A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the search Danny Sullivan. The Parts of a Crawler-Based Search Engines. search.php. 2. Program yang digunakan oleh mesin pencari untuk mengakses laman web disebut spider, namun pada kondisi tertentu dikenal dengan nama lain seperti crawler, robot atau bot. What is search engine give 5 examples? Tor Browser:- Tor browser is the main key point of entering the dark web.
Pages are ranked by a mathematical formula called an algorithm. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database. A search engine is a software system designed to carry out web searches.They search the World Wide Web in a systematic way for particular information specified in a textual web search query.The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). The Sitemaps protocol is based on ideas from "Crawler-friendly Web Servers," Support for the elements that are not required can vary from one search engine to another.